The Qikest way to run
Local & Remote AI.
Stop babysitting your terminal.
A complete local AI orchestrator in one tiny binary. A full web console, a built-in premium chat UI, and
run your own llama.cpp or vLLM engine side by side with remote API providers, all through QikLM.
No CLI, no Docker, no bloated
Electron install. It's running in seconds.
One Binary, Zero Dependencies
No electron apps, no Docker, no npm, nor python installs. Boots in seconds.
Local Engines & Remote APIs
Run llama.cpp or vLLM locally, side by side with external OpenAI-compatible providers, all through one unified API.
Smart Model Profiles
Save your cli flags once. Switch models with a click or let QikLM swap automatically on prompt.
Web UIs & Network Access
Admin dashboard, PromptUI chat, and GPU monitoring from any browser on your network.
Run Qwen 3, Gemma 4, Llama 4, DeepSeek R1, Mistral, Phi-4, GLM-4, and any GGUF or Hugging Face model locally.
Download QikLMFree for personal and work use.
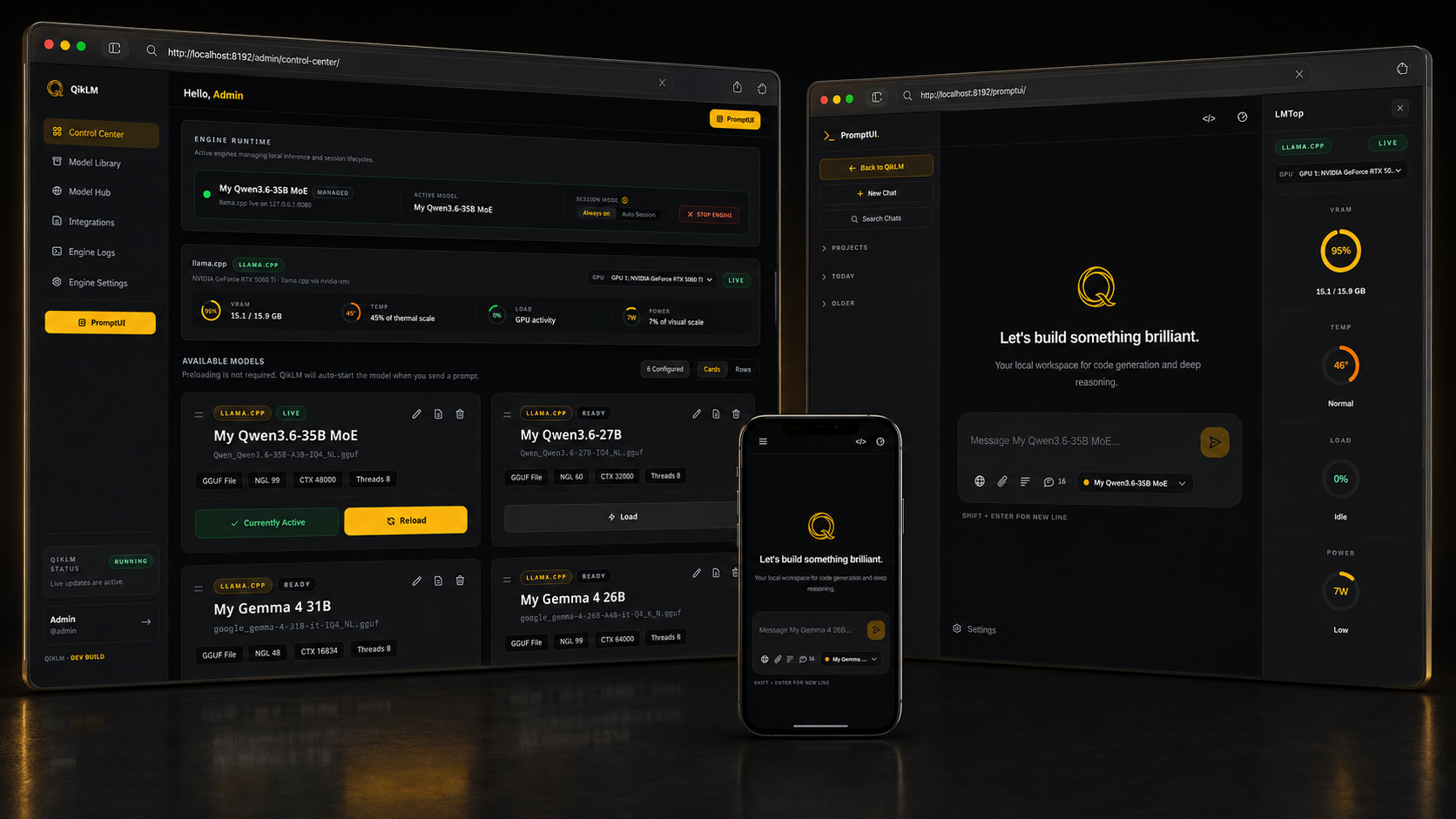
Professionalize Your
Local Inference.
Local AI is powerful but managing it shouldn't feel like a second job. QikLM handles the complexity so you can focus on using your models.
Bring Your Own Inference
Stop waiting on proprietary launchers to update their embedded engines. Run any llama.cpp or vLLM build to access the latest features instantly, or let QikLM install a llama.cpp Github release for a quick setup.
Seamless Agent Integrations
Connect Claude Code, Codex, Hermes Agent, OpenCode, and other OpenAI-compatible tools through the built-in integrations panel.
100% Offline & Network-Ready
Zero cloud telemetry. QikLM runs on your hardware and serves a Web UI you can reach from any device on your network. Already on Tailscale or a VPN? Manage your local AI from anywhere, with no extra setup.
Orchestration.
Not
Configuration.
QikLM sits between your apps and your inference engine, turning manual terminal work into a persistent background service. Your apps talk to QikLM, and QikLM handles the rest.
Instant Boot
Automatically starts your engine on your first prompt.
Unified API
Use local models alongside external OpenAI-compatible APIs, all through one endpoint.
Lifecycle Sync
Automatic loading and unloading of server processes.
Seamless Swapping
Hot-swap models mid-chat without manual restarts.
lmtop
Native Hardware Observability
Universal GPU Telemetry Engine
VRAM
12.9/16G
Temp
49% Scl
Load
Idle
Power
6% Scl
Custom Architecture lmtop is QikLM's native telemetry engine: built from scratch to deliver zero-dependency, real-time observability for professional AI workflows.
Engine Control.
Without
Limits.
QikLM gives you full command over your model weights. Save configurations as Profiles to instantly load your favorite setups, and use Templates to standardize recurring parameter values across your entire library. No more babysitting terminal switches and scripts.
Reusable Profile Templates
Create templates to instantly seed new model profiles with your preferred defaults instead of entering the same values every time.
Profile-Based Startups
Save your setup once. Configure all the necessary flags you need for each model directly in your profile. You can even choose different llama.cpp builds per model profile.
Full CLI Passthrough
The UI presets cover the common flags, but every profile also has a raw CLI argument field. Pass any llama.cpp or vLLM flag you need and save it to the profile.
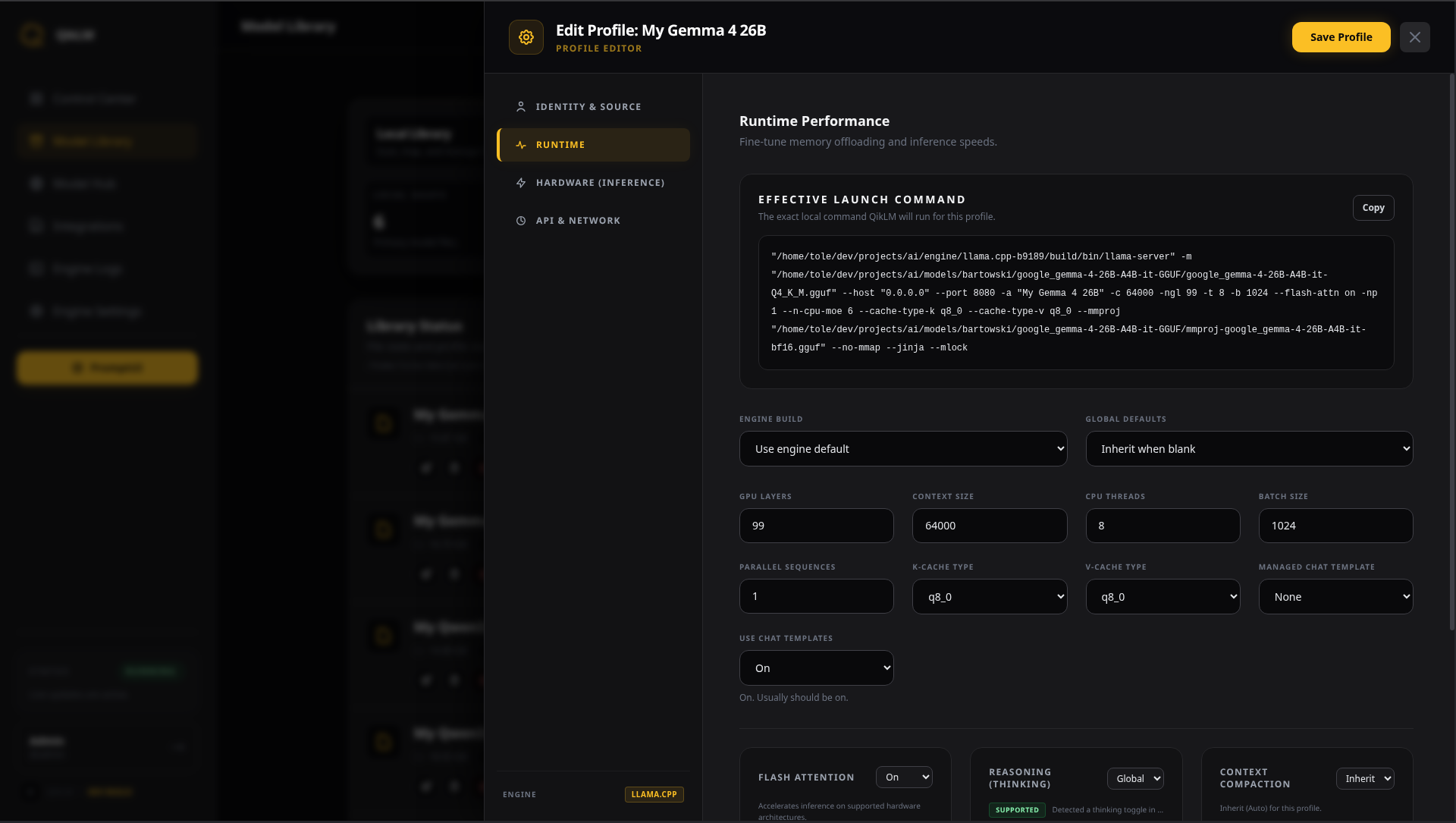
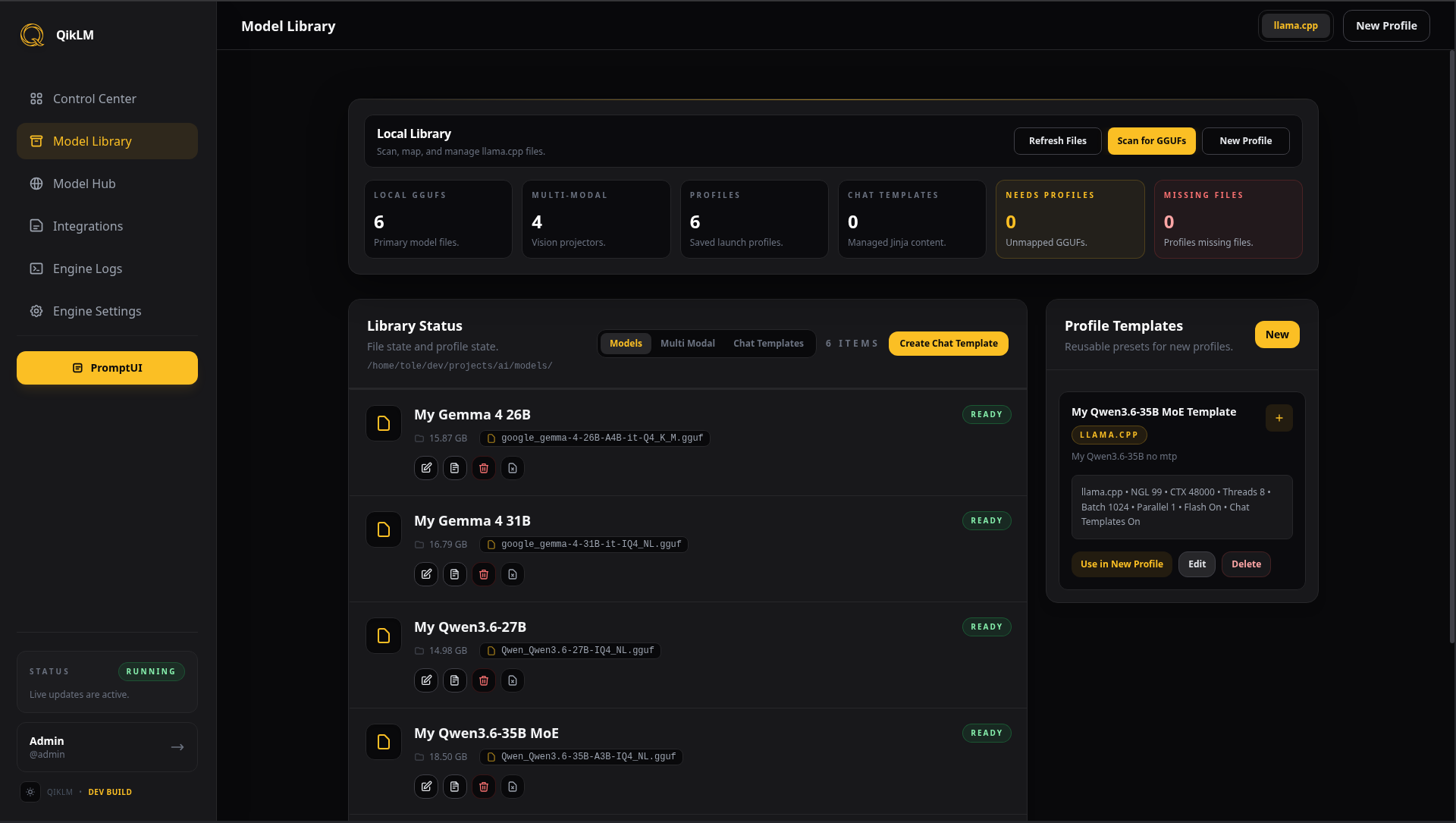
Automated Library
Management.
QikLM organizes your weights into a unified model directory, automatically maps LLM files to searchable profiles, and manages your entire collection through a clean, actionable hub.
- Automated discovery and profile mapping.
- Reusable Model Templates for faster setups.
- One-click deletions and library refreshes.
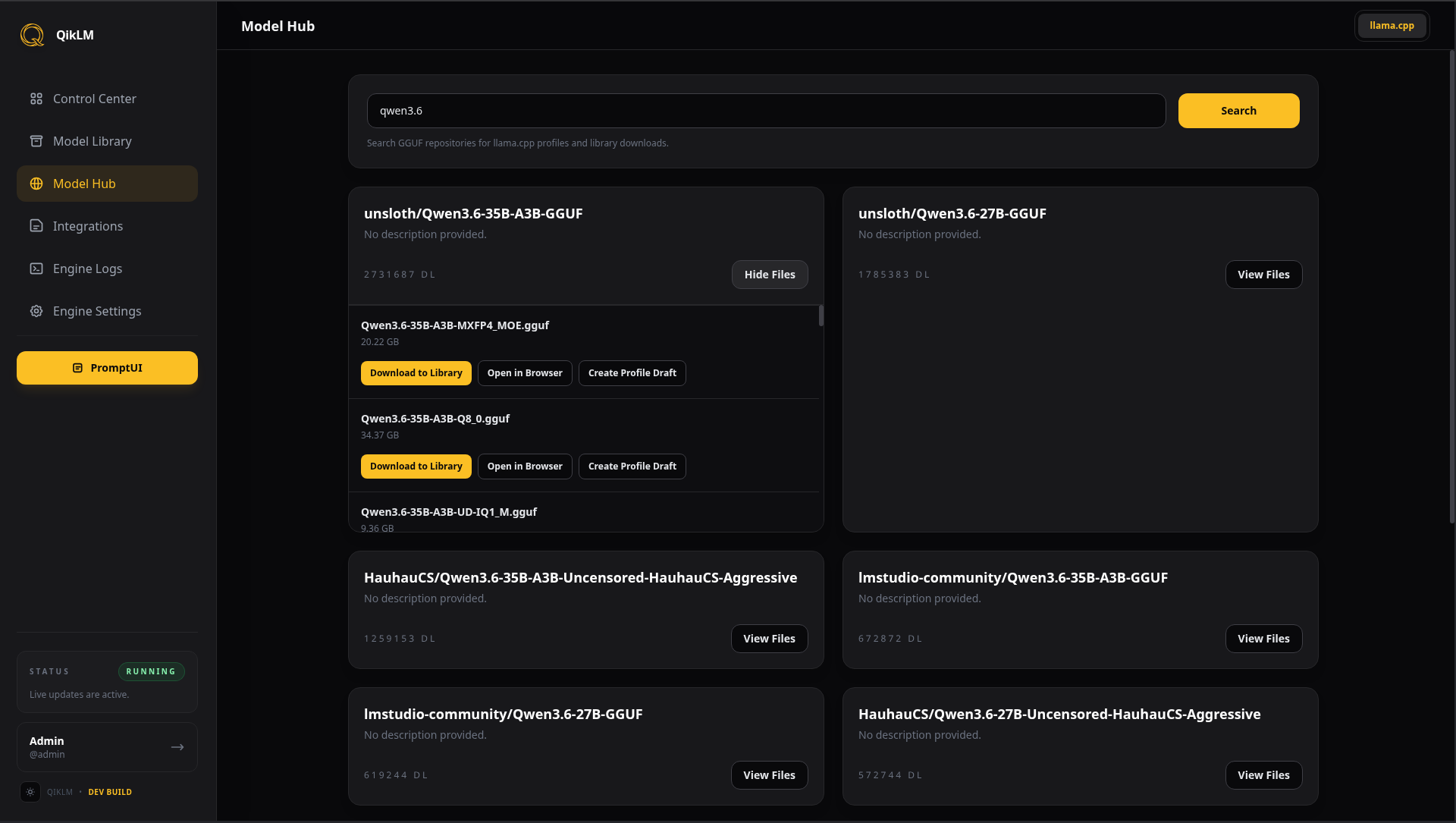
Explore the
Model Hub.
Easily browse and download your favorite open weights including Llama, Qwen, Gemma, Deepseek, Mistral, and millions more directly into your library without ever leaving the UI.
Direct Search
Universal HF repository index.
Tree View
Inspect quants before downloading.
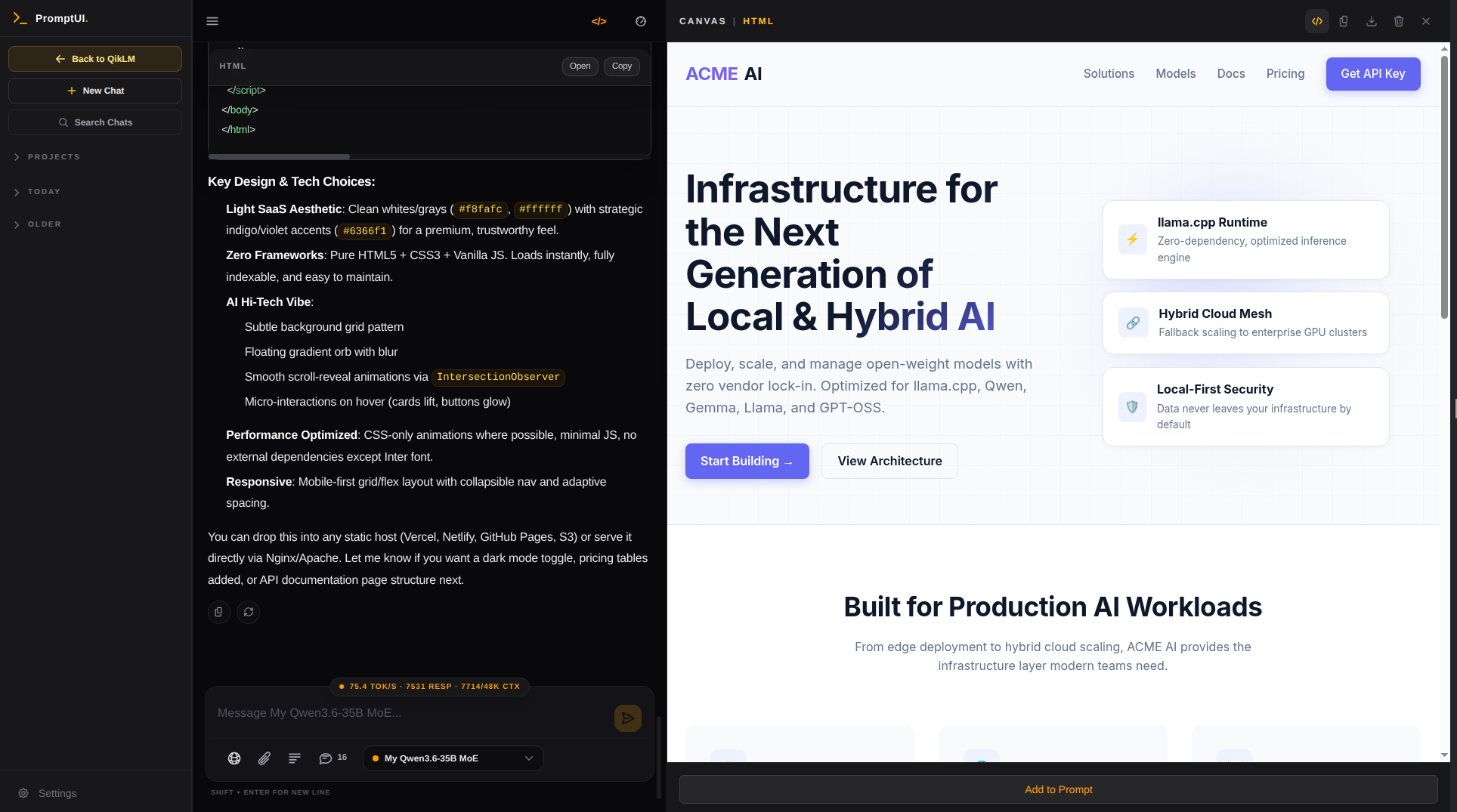
PromptUI: The
Built-in Chat Interface.
A premium chat GUI and coding workspace with a built-in Interactive Canvas for live code collaboration and webpage previews. Monitor performance with lmtop gpu monitor directly in the slideout panel.
Workspace Projects
Manage persistent chat histories across dedicated projects.
Documents & OCR
Attach images, PDFs, and Office documents. Built-in OCR extracts text from images and scanned PDFs automatically.
Interactive Canvas
Live-edit code and preview HTML pages directly in the workspace.
Brave Web Search
Optional live search integration to ground models in real-time data.
MCP Resources
Inject dynamic context via user-selected HTTP MCP endpoints.
Designed to Play Nice.
QikLM isn't just a standalone tool: it's a high-performance orchestration core that powers your favorite local AI frontends, agentic workflows, and any OpenAPI-compatible interface.
Claude Code
- Native support for Anthropic's Claude Code CLI.
- Automated environment preparation and model bridging.
Codex
- Dedicated profile support via the QikLM Responses API.
-
Execute
codex --profile qiklmagainst any local profile.
Hermes Agent
- Custom provider and model profiles for instant routing.
- Native compatibility with high-performance local inference.
OpenCode
- Zero-config model discovery in the OpenCode TUI.
- Hot-swap profiles without restarting your terminal.
Tons of features built-in
QikLM ships with a massive feature set designed to make local AI management effortless.
Bring Your Own Keys
Need a cloud model for a task? Add your own OpenAI, Anthropic, or OpenAI-compatible key and use it right alongside your local models. Optional, and entirely yours.
Smart Model Profiles
Save common engine configs for every model including GPU layers, context, threads and any cli args you wish to use.
lmtop Gauges
Real-time hardware observability. Monitor VRAM, power, and thermals in live gauges.
Model Library
Turn your weights folder into a proper management hub with file discovery and scanning.
HF Explorer
Search Hugging Face, inspect file trees, and download LLMs directly to your storage.
Auto VRAM Unload
Automatically frees GPU memory after periods of inactivity to save power and resources.
Profile-Based Startups
Stop remembering complex terminal flags. Save your entire configuration into a profile, pick your preferred engine build, and launch with a single click from the UI.
Ecosystem Ready
Seamlessly power Claude Code, Codex, Hermes Agent, OpenCode, OpenClaw, and any OpenAI-compatible completions and responses API with QikLM's orchestration core.
Zero-Bloat Deployment
A single, lightweight binary with no dependencies. Designed to stay fast, stay out of your way, and run anywhere.
Systemd Ready
Professional .deb and .rpm packages that set up QikLM as a background systemd service. No separate daemons required.
Model Swapping
Seamlessly swap backend inference engines mid-chat with any OpenAI-compatible client.
Multi-Binary Support
Swap between different llama.cpp builds and versions per model profile. Maintain multiple engine forks and releases to ensure peak performance for every model.
OpenAI Compatible
Support for v1/completions and v1/responses endpoints for all major modern AI frontends.
Local. Private. Fast.
Get started with QikLM and take full control of your local AI setup.
Download QikLMFree for personal and work use.